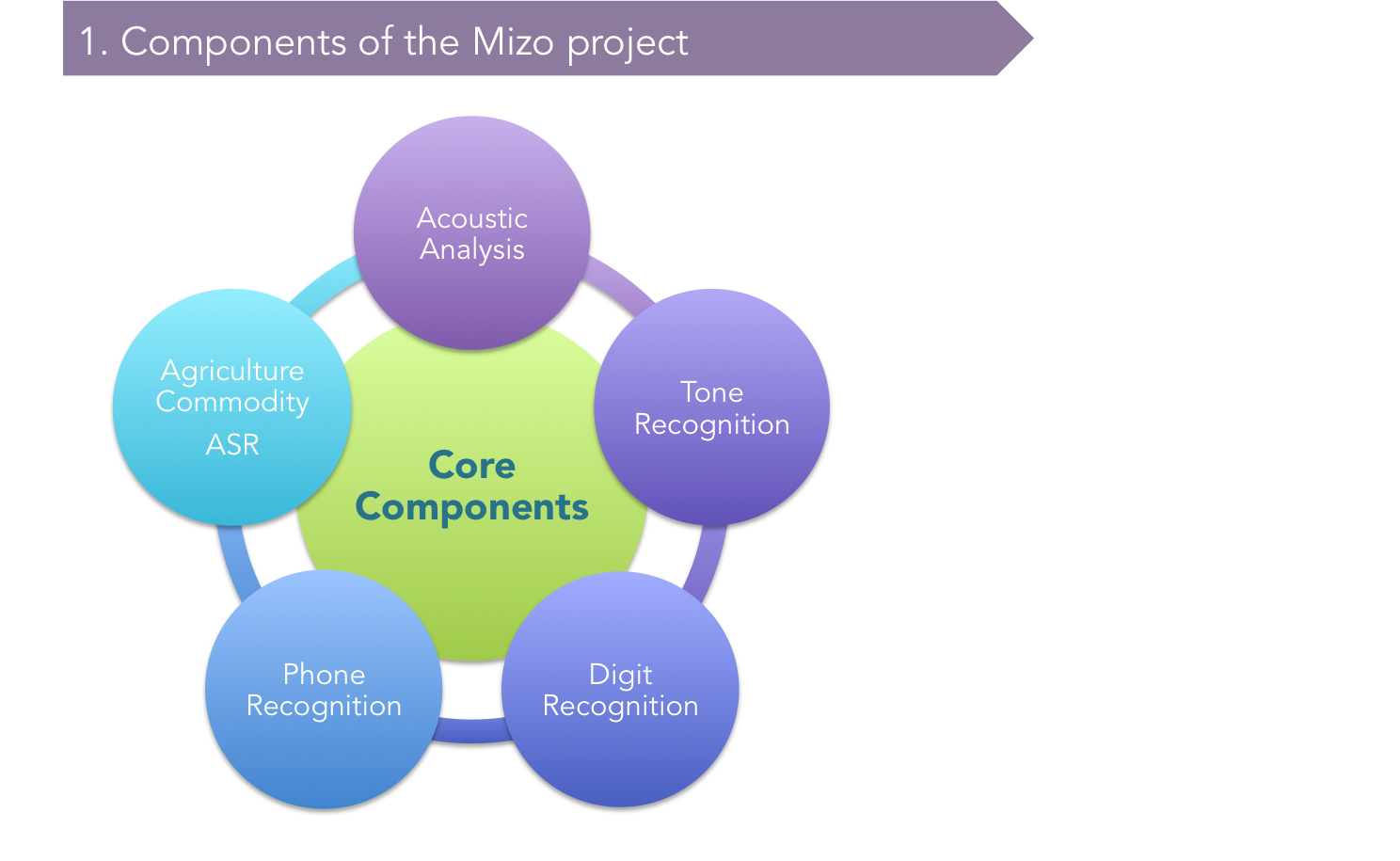
Mizo is spoken in the North-East India with about a million speakers for each language. These two languages belong to the Tibeto-Burman family of languages. Even though Mizo has sizable native speakers, not much work has been done on it either from the speech technology or from the linguistic perspective. For example, there is no reliable inventory of acoustic features for Mizo as of now.
Mizo, is spoken in parts of North East India, that are geographically isolated even from the other parts of the region. Consequently, this area suffers from a significant hurdle in terms of information accessibility and transmission. Hence, there is a need to compensate the provinces for the information blackout it is suffering due to geographical isolation. Such compensation can be provided through mobile technology with a minimum need for infrastructural overhaul. Hence, the outcomes of this proposal will potentially build the base for creation of systems that will enable access and retrieve information using voice prompted commands over mobile network. Considering the two viewpoints stated above from linguistic and information technology perspectives, the objectives of this project are manifold. The primary objectives of this project are outlined below:
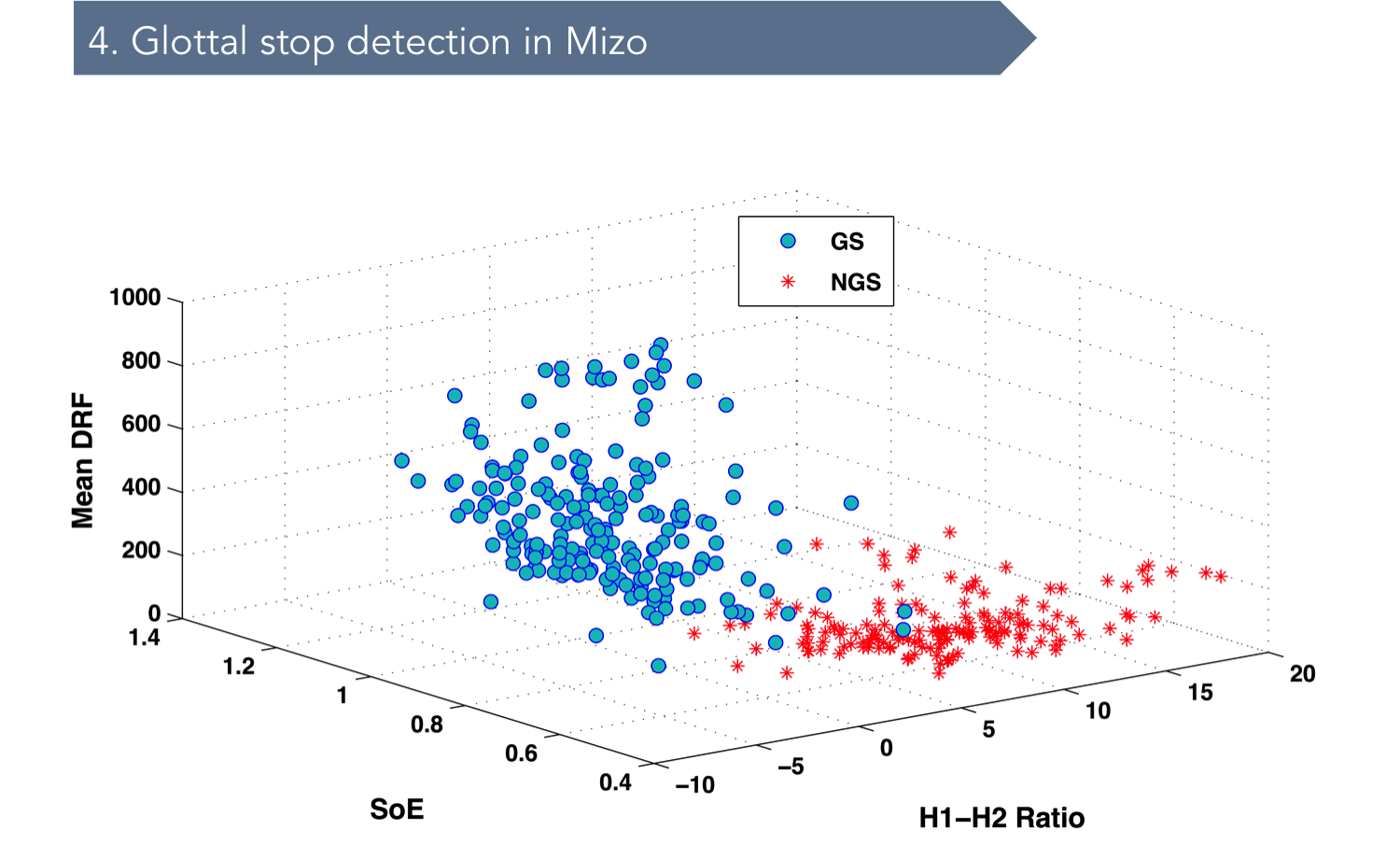
• Speech data collection from the native speakers of Mizo. • Conduct acoustical analyses on the data. • Extraction of segmental and tonal features. • Acoustic phonetic description of the segments and tonal features of the two languages.
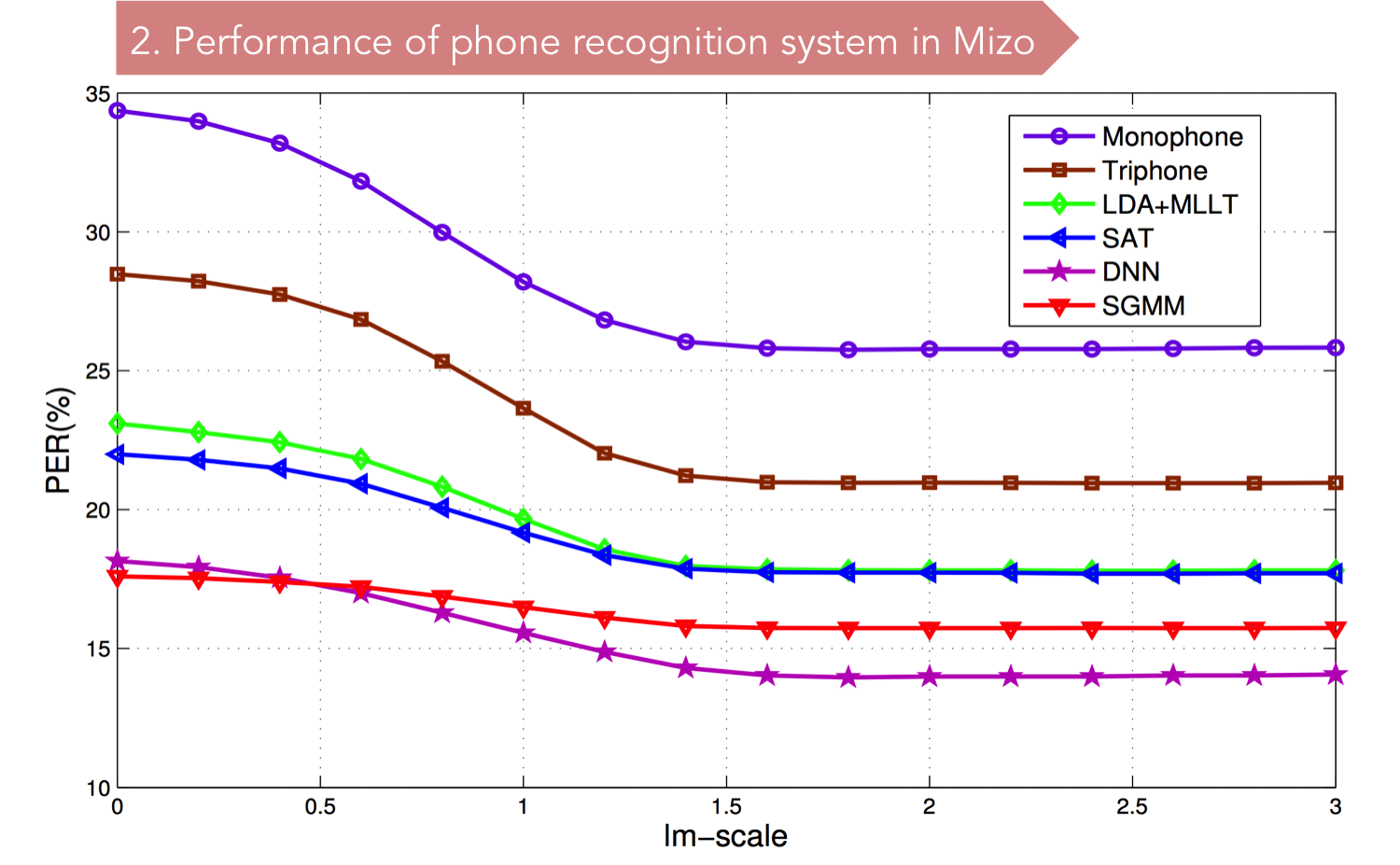
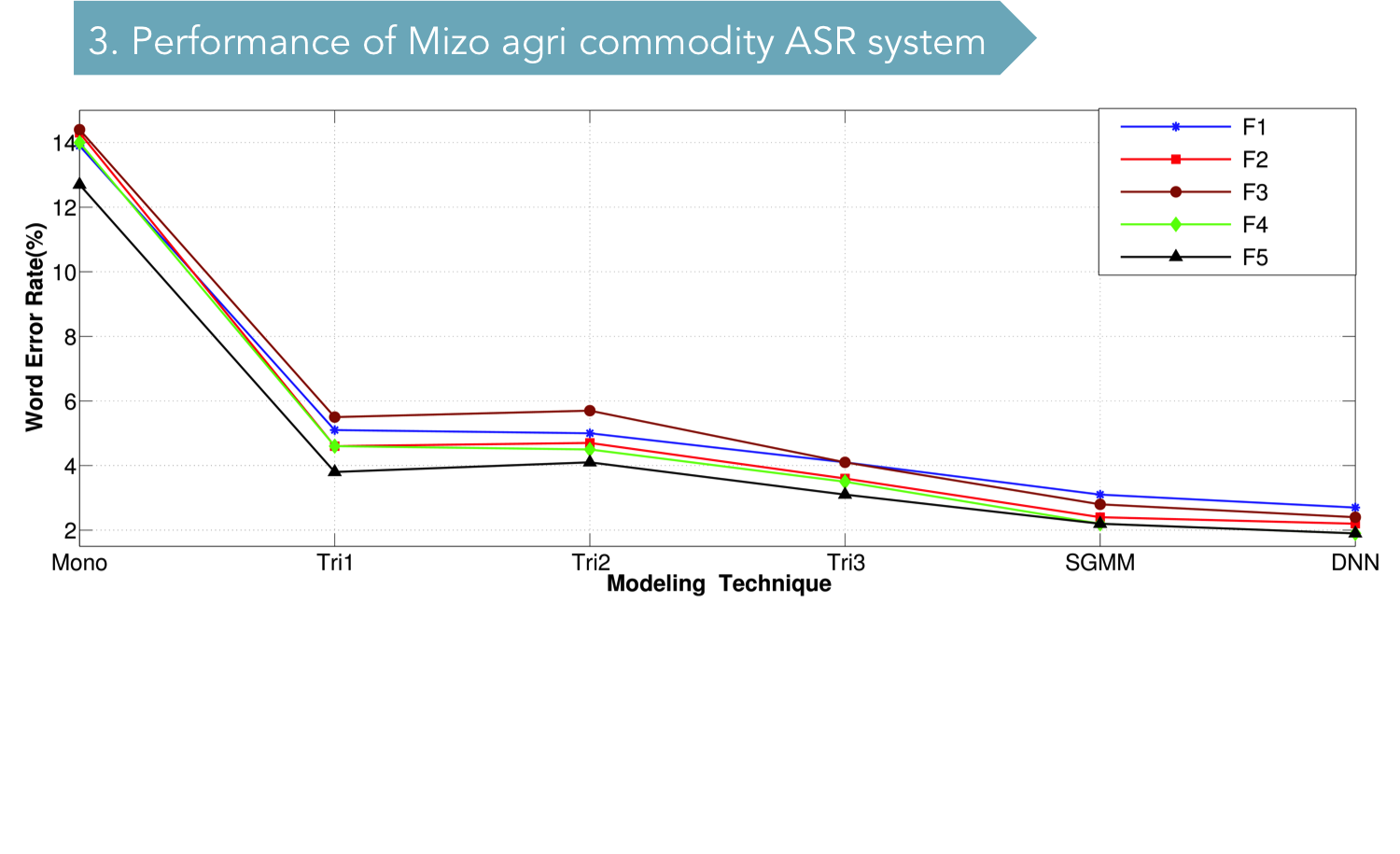
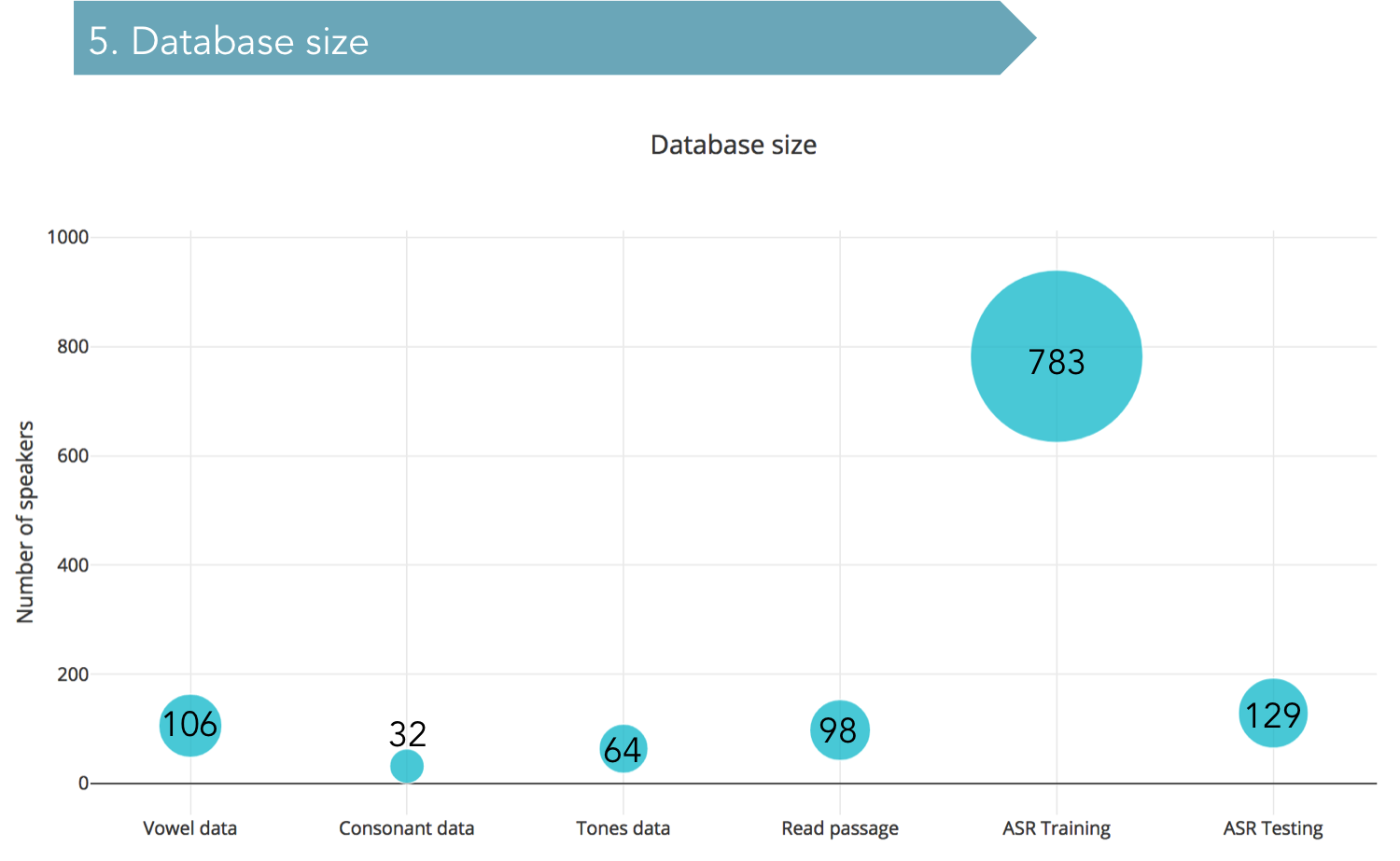
Mizo is a tone language such as Mandarin Chinese and if one intends to build an effective ASR system for it in the future, information about the acoustic and tonal features of the language will be very important. Hence, one of the objectives of this project is also to do a careful feature extraction of Mizo speech with special focus on tones. By far, in India, no ASR system has taken the tonal aspect of the languages into consideration. Hence, in that sense, this project may be a breakthrough into the domain of ASR systems built for tone languages in India. Another byproduct of this project is a speech corpus of Mizo. Mizo, despite of it having a large number of speakers, does not have much linguistic or speech technology related studies conducted on them. Hence, the data collected for tonal and segmental feature extraction in this project may also serve as a substantial speech corpus for future researchers who intend to work on the language. We are planning to make the speech corpus available online to interested scholars on-demand.