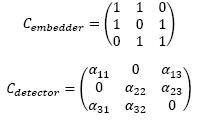Dr. Kannan Karthik (Homepage - will be updated soon...)
Associate Professor
Department of Electronics and Electrical Engineering
Indian Institute of Technology Guwahati
Guwahati, Assam - 781039, India
Contacts: k.karthik@iitg.ac.in
Cell: +91-9957215409; Office: +91-361-2582516
![]()
![]()
![]()
![]()
![]()
![]()
![]()
 (NEW)
(NEW)
Last updated (selectively): August 9, 2023 [Teaching profile and Publication list and RESEARCH PAGE BELOW]
Notes and scribbles on Creative and constructive thinking (updated: October 21, 2015):
![]()
![]()
![]()
![]()
![]()
Courage and conviction

|
Caption: And I still maintain that the world is a PYRAMID, where the voices of a few pure individuals cannot go un-noticed. Nobody can take away your self-respect, unless you give it to them. - Mahatma Gandhi |
|
The process of creation evolves only when the creator detaches himself from what is being created. |
Teaching assignments (past with present highlighted)
EE692: Detection and Estimation theory (Aug to December 2022/23) [CURRENT]
EE522: Statistical Signal Processing (Jan to May 2023)
EE230: Probability and Random Processes (Jan to May 2020/21)
EE204: Circuit Theory (July to Nov 2019/20/21)
EE636: Detection and Estimation theory (Jan to April 2018/2019)
EC636: Detection and Estimation theory (Estimation part) (Jan-Apr 2009)
EE660: Biometrics (July to Nov 2018; Jan to May 2022)
EE525: Optimal and Adaptive Signal Processing (Jan to April 2015/2016/2017)
EE531: Communication System Theory (current: Aug to Nov 2015/2016/2017)
EE521: Digital Signal Processing (Aug to Dec 2012)
EC331: Communications Lab (Aug to Nov 2010/2011/2012/2014)
EC638: Multimedia Security (Jan to May 2011/2012/2013/2014)
EC330: Digital Communication (Aug to Nov 2010/2011)
EC230: Principles of Communication (Jan-Apr 2010)
EC320: Digital Signal Processing (Aug-Dec 2008/2009/2013/2014)
EC333: Communication Networks (Jan-Apr 2008)
Criteria for applying to our research group
| The quest to seek is one of the greatest addictions in itself. So it should be for any budding researcher who is working hard to gain a better understanding of any problem, which, in its initial stages is nothing but an unfinished sculpture. |
I am looking for highly motivated, enthusiastic students with a sound academic record to pursue several open-ended problems.
Students satisfying the following CRITERIA may approach me for a B.Tech/M.Tech thesis project, hardware design lab or any other short term assignment.
Potential and/or partially attacked Research Problems (Updated: December 8, 2022)
Graph based Machine learning Models for profiling sparse and heterogeneous data (Jan 2022 onwards)
When the application-centric data available is compact and homogeneous, clustered into distinct ellipsoidal blobs and the data-size/volume is large, it is easy to construct a data-centric model for it. However, when the class data is heterogeneous and sparse in nature, it is extremely difficult to synthesize a parametric model of a geometric nature to encapsulate the in-class data. Often such heterogeneous and sparse data tend to leave us in a conundrum:
a) If these sparse data-points are truly representative of the underlying physical phenomenon and the diversity that prevails therein, then an over-generalization attempt to fit in a multi-dimensional ellipsoidal blob will not be justified.
b) Shape based profiling is a possibility by identifying the geometric back-bone of the data using some form of graphical analysis [Wang-2012-MST], but proper bounds can be established only when the data is skewed having an arbitrary geometric shape in a particular multi-dimensional space but is largely homogenous as far as this cluster is concerned.
The problem breaks down when the data is:
1) LIMITED in size/LOW-volume
2) SPARSE and arbitrarily scattered albeit with some correlation (difficult to associate a local-density parameter with this data).
3) Heterogeneous (largely spatially non-stationary; locally may exhibit some weak correlation with its neighbours)
The only way such data-sets can be profiled is via SPANNING TREES [MST-Gower-1969].
[MST-Gower-1969] Gower, J. C., and G. J. S. Ross. Minimum Spanning Trees and Single Linkage Cluster Analysis. Journal of the Royal Statistical Society. Series C (Applied Statistics), vol. 18, no. 1, 1969, pp. 54 64. JSTOR, https://doi.org/10.2307/2346439. Accessed 8 Dec. 2022.
[Wang-2012-MST] Wang, X., Wang, X.L., Wilkes, D.M. (2012). A Minimum Spanning Tree-Inspired Clustering-Based Outlier Detection Technique. In: Perner, P. (eds) Advances in Data Mining. Applications and Theoretical Aspects. ICDM 2012. Lecture Notes in Computer Science(), vol 7377. Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-642-31488-9_17
In the collaborative thesis-linked work with Shoubhik Chakraborty [Ongoing current PhD-work under review], we claim that a DUAL formulation linked to MIN and MAX-spanning trees can be used to pick-off outliers of different types from a single cluster arrangement;
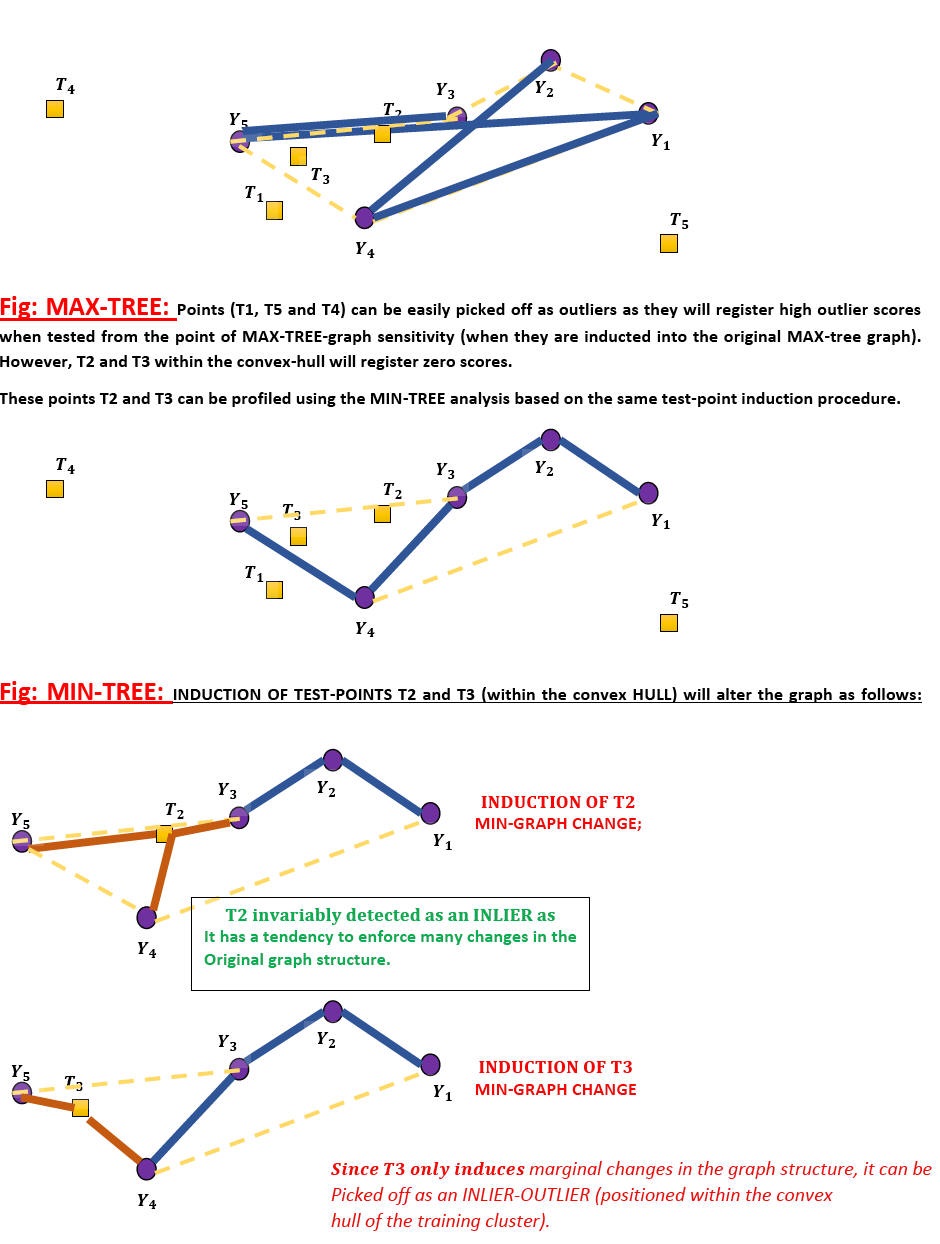
Depth Map generation from single natural images using Contiguous Random Walks (December 2021 onwards):
Natural images when captured carry not only overt information regarding the "scene" in front, but tend to get embossed with IMMERSIVE ACQUISITION NOISE. This acquisition noise is a function of the interplay between the
(i) Environment (which may contain many objects, partially or fully occluded at different spatial locations and different depths),
(ii) The local illumination profile (e.g. positioning of the sun in relation to the objects and the camera, i.e. the local illumination profile) and
(iii) The camera pipeline which includes the LENS-SYSTEM.
This acquisition noise can be trapped and profiled in an EFFICIENT and CONTENT AGNOSTIC fashion, using CONTIGUOUS RANDOM WALKS over different parts of the INTENSITY IMAGE. Such walks had been used in the past in 1987 by Mathias and Shamir for compressing encrypted videos using SPACE FILLING CURVES [SPC-1987] and later adapted to detect FACE-SPOOFING (both PLANAR TYPE and PROSTHETIC based) in Balaji and Karthik [PAA-2020]. It was found in [PAA-2020] that when these scans were deployed in auto-population mode, the first, second and third order scan differential energy statistics carried significant information regarding the acquisition pipeline, particularly the micro-noise revolving around the acquisition process.
Since the first, second and third order pixel-intensity correlation statistics get trapped using these locally executed random scans, they can be used to effectively determine the statistics connected with locally stationary and slowly varying micro-acquisition noise patterns. Natural images exhibit a space varying blur depending on the relative positioning of the objects in relation to the camera-lens-system. This is because of the PIN-HOLE camera effect.
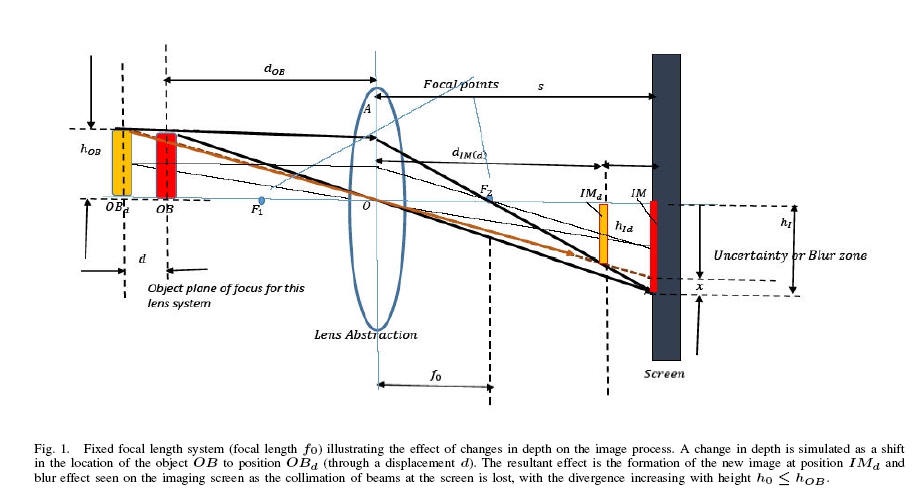
This blur diversity, which in some way is inversely proportional to the depth-variation relative to the OBJECT PLANE of focus can be trapped using these RANDOM SCAN statistics.
[SPC-1987] Matias, Y., Shamir, A. (1988). A Video Scrambling Technique Based On Space Filling Curves (Extended Abstract). In: Pomerance, C. (eds) Advances in Cryptology CRYPTO 87. CRYPTO 1987. Lecture Notes in Computer Science, vol 293. Springer, Berlin, Heidelberg. https://doi.org/10.1007/3-540-48184-2_35
[PAA-2020] Katika, B.R., Karthik, K. Face anti-spoofing by identity masking using random walk patterns and outlier detection. Pattern Anal Applic 23, 1735 1754 (2020). https://doi.org/10.1007/s10044-020-00875-8
Graphical Example of such a pseudo-contiguous random walk is shown in the figure below.
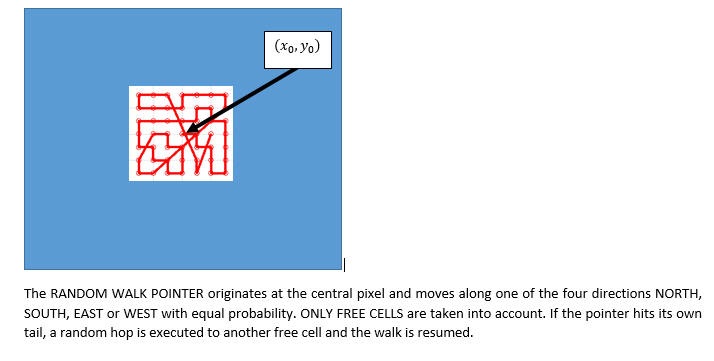
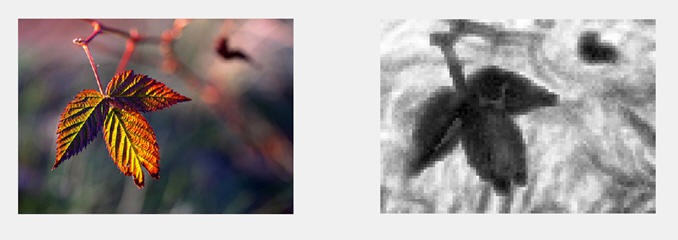
Exemplar depth maps computed using differential random scan statistics are shown below:


Facial Anti-spoofing based on Natural Blur/Sharpness Analysis (December 2017):
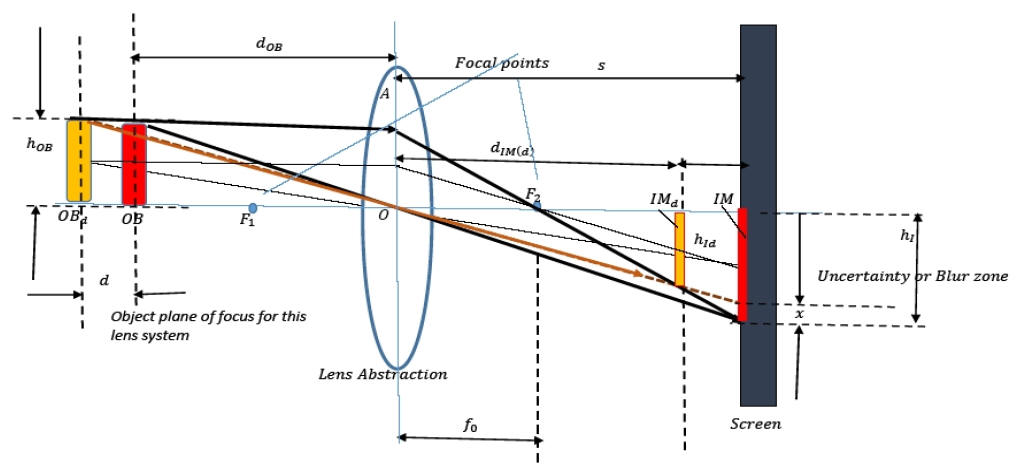
In a typical CAMERA IMAGE CAPTURING process (particularly in a ZOOMED IN STATE), the cameraman auto-adjusts the camera to focus clearly onto an object such as a face. While the auto-adjustment may indicate extreme clarity throughout the image, there will be non-homogeneous gentle blur differential throughout the natural face image captured. This blur differential stems from the fact that based on the PINHOLE principle, the object plane or the plane of focus is the only part of the face which will appear with absolute clarity. Any plane at a distance away from this object plane (either in front or behind) will appear blurred as a function of the distance from the object plane and the direction of movement. The captured NATURAL face will exhibit a NON-HOMOGENEOUS BLUR as function of the relative depth of the object. The first two images are examples of SPOOFINGS (planar versions) while the third one is a NATURAL PICTURE.
 (1)
(1)
 (2)
(2) (3)
(3)
When a photo of a photo is taken, firstly it is extremely unlikely for the object plane to coincide exactly with the plane of the photo. As a result of this there will be a cumulative blur which can be exploited to pick up the SPOOFING of this nature (model specific).
Privacy preserving filtering (September 2017):
By imposing natural constraints on the encryption process, it is possible to achieve signal obscurity (ensuring sufficient privacy while processing the signal in the encrypted domain), while at the same time leaking sufficient information to permit a preliminary classification or clustering in the encrypted domain. One potential construction in this vein is shown below using MINIMUM PHASE FIR filters.

Visual Cues that impart depth to STILL PORTRAITS and IMAGES (July 18, 2015):
For a moment step aside and examine the image below. Can you envision the MAIN TREE in 3D space? To start spend a little bit of time picking out patterns which impart depth cues. You will find that the human eye and mind has a remarkable ability to reconstruct 3D versions of planar projections of complex objects such as TREES. Is it possible to tell which branches are coming towards the viewer and which ones are moving away from the viewer?

Source: http://shawnmccauley.com/news/wp-content/uploads/2012/11/trees3.jpg
HINT: Most trees exhibit bifurcations in their branch structure to maximize leaf exposure to sunlight. Hence, the shadow above of this post-winter tree exhibits an almost fractal-like inverted lightning effect with the forks becoming progressively smaller as the branches reach the RADIAL saturation point (i.e. summit of the UMBRELLA). Interestingly this FORK is a very useful GEOMETRIC PATTERN which provides depth information based on its hinge point in space and orientation. One possible depth interpretation is given below.

De-noising images and recorded music in the encrypted domain (July 2015):
Content transparency is a growing concern in large scale media networks. While encryption schemes help in protecting the content from anonymous sniffers, they have a tendency to dissolve almost all statistical patterns which are content-definitive. Permitting content transparency for applications such as image classification, secure authentication etc. have been studied in our earlier formulations [KKSACH13, MANI13, HAR14, TOM15], where certain patterns native to the image construct are allowed to penetrate the encryption algorithm making them available for further analysis and comparisons. Taking this one notch higher, the following questions may be asked:
1) Is it possible to perform a quality assessment of the recorded media (without or with side-information) in the encrypted domain?
Interestingly, the problem of BLIND-Image Quality Assessment is in itself extremely challenging. By further streamlining the availability of information for quality assessment in the encrypted domain, the problem acquires a new dimension with this BLIND SOURCE SEPARATION problem now being linked with the notion of content secrecy.
2) When it comes to recorded music (pirated or legitimate), there are several parameters which define "quality" - (i) Absence or minimal background noise, (ii) Elimination of unwanted reverberations only (Note: controlled reverberations sometimes simulate GAMAKAS and create a more vibrant artistic effect. It is advised to leave them intact in the recordings). Is it possible to detect any of these detrimental effects in the recordings without exposing the composition?
Hence the process of quality assessment in the encrypted domain has nice implications on the application front due to its privacy angle.
[KKSACH13] K. Karthik, S. Kashyap, Transparent Hashing in the Encrypted Domain for Privacy Preserving Image Retrieval , in Springer Journal of Signal, Image and Video Processing, Special issue on Image and Video Processing for Security, Vol. 7, No. 4, pp 647-664, July 2013.
[TOM15] Tom Sebastian, Privacy preserving face detection and its application to face recognition based on composite masks, MTech thesis, 2015
[HAR14] Harshit B, Privacy preserving face biometric comparison, MTech thesis, 2014
[MANI13] V. Manikanta, Face retrieval based on Eigen-correspondences, MTech thesis, 2013
Automated quality assessment in encapsulated and non-encapsulated files (July 2015):
The wide-spread use of integrated multi-functional mobile devices for recording conversations, scenes, events on the move has opened up an issue pertaining to quality. These recorded files are transferred through packet networks either on a peer-to-peer basis or through selective multicast channels both of which are supported by MOBILE APPLICATIONS SUCH AS WHATSAPP. While peer-to-peer transmissions are personal conversations and these personal conversations to some extent guarantee authenticity and quality of information transferred, this is not guaranteed in multicast networks. In a selective mobile-app geared for multicast, an individual releases a file to a mass or group which does not have a UNIQUE IDENTITY. Subsequently this notion of sending a file to a BLOB of people, does not bring with it a moral responsibility, as it would have if the conversation was directed at a single individual with a distinct personality. Quality checks can be performed by moderating the content, but manual moderation requires the presence of an individual (available at all times), to parse and scrutinize the content before allowing it to funnel to the other people in the network. While this implementation is ridiculous for SPONTANEOUS APPLICATIONS such as WHATSAPP which thrives primarily on "text chats", it becomes much harder for encapsulated audio and video files (which must be decompressed/scrutinized and then recompressed before permitting its multicast). Breaking the flow of the conversation will have several commercial repercussions and hence such systems cannot be implemented.
The following questions can be raised:
The notion of transparent compression:
The process of compression has several layers and at each layer information richness is preserved at the price of a change in perspective, in the way the signal is understood (or viewed). For example, as an image in the spatial domain is mapped to the BLOCK-DCT domain, the perceptual reading is lost partially. As one drifts from the QUANTIZED-BLOCK-DCT domain, to the BIT-DOMAIN (HUFFMAN/VLC coded domain), a block of quantized coefficients are mapped to a binary string which appears as a PSEUDORANDOM IID string. In a PSEUDORANDOM IID string, all possible binary sub-sequences appear to be equally likely. A PSEUDORANDOM IID string is virtually unreadable without complete decoding. However when a PREFIX code is used, there are implicit constraints on the permissible combinations of sub-strings. Thus is it possible for the BIT-PARSING UNIT to perform some preliminary analysis on this string to estimate the noise floor when the dictionary is known?
Swarm based texture identification and classification: "Tasting natural scenes" (November 2014):
Target IMAGE

Swarm selection for search and association

An expert cook, can easily tell by sampling a dish that its seed ingredients are most likely to be A, B, C... Most dishes are carefully designed mixtures of only a few specific elements present in different volumes. Thus a DISH is defined by two distinct elements: 1) TYPE and DISTINCTIVENESS of the basic ingredients; 2) Relative volumes of the ingredients. The beauty about a well-prepared dish is HOMOGENEITY or UNIFORMITY or CONSISTENCY throughout the dish. The implication of this property is that even a small part will represent a whole. This allows the cook to sample only a small part of the dish and use it for analyzing its contents. If we extend this idea to elements and objects in an image, can we define some elemental constituents of a natural scene such as SKY, WATER, SAND, MOUNTAIN, ROAD, PEOPLE, FACES of PEOPLE, SHRUBS, TREES etc.. Shown above are two images which belong to the same family of desert sands. The question is: Is it possible to ASSOCIATE THE TWO? The answer is YES to any HUMAN OBSERVER but may be difficult to AUTOMATE. But when the user defines what needs to be examined as a feature (or rather needs to be mimicked in relation to the human observer), the feature extraction process becomes specific to the content being examined and compared, i.e. DESERT SAND. Some much more challenging examples are shown below (e.g. DETECTING MIST). The key element which could be useful in defining MIST is "partial transparency" or "Fuzziness in the view" or "lack of clarity". Unless this is quantified by an appropriate selection of features, the search and matching process will not be effective. The following are some examples of search queries. Do these queries adequately define the subspace of scenes carrying mist?



Health diagnosis based on VOICE ALONE (September 2014):
"BREATH IS LIFE and LIFE IS BREATH".
This is not an understatement by any means for BREATH is CONDUIT to the VITAL FORCES INSIDE OUR BODY [BKS_IYENGAR]. Without this pulsating river which drives the machinery inside us, LIFE and INTELLIGENCE in all respects will cease to exist. Most ancient religions and spiritual belief systems also concur on one point: that the breath is a gateway to the mind. The MIND and the BREATH are elastically inter-linked, where one can perturb the other or put in a different way one can be used to exercise control over the other which forms the essence of practices such as PRANAYAMA.
Hence the breath can be used as an excellent diagnostic tool for gauging both psychosomatic problems as well as other respiratory problems. While this breath drives the machinery inside us, it also serves as a VIBRATORY HUB for facilitating any form of VOCAL DIALOGUE between individuals. A lot can be inferred about the state of the physical and mental health from the clarity and effectiveness of the VOCAL COMMUNICATION. On one hand the VOICE of any individual carries the following fragments of information: 1) Emotional state of the individual, 2) Command over the language spoken - this has two sides: richness and clarity (which may also be a measure of depth: as they say, "When the waters are clear one can see the bottom), 3) Cultural influence reflected as accent, 4) State of awareness etc. On the other side, since the breath is intertwined with the voice and in fact drives the vocal chords, the question we raise is whether this can be used for a detailed health diagnosis. The wheels of the body are excited by certain key PHRASES (analogous to channel excitations in communications systems). The PHONEME PERTURBATION pattern may be used to predict the onset or ascertain the presence of any illness (respiratory or non-respiratory). The trick however is the separation of all those FOUR unwanted fragments from the desired health information. Maybe this can be done by a trained medical practitioner. But can this be AUTOMATED?
Variations include specifically designed HUMMING SEQUENCES: 1) NON_CLASSICAL (Nursery Rhymes type), 2) SEMI_CLASSICAL and 3) CLASSICAL, where the last two are difficult to emulate for any untrained vocal artist leaving behind larger interference patterns.
BKS_IYENGAR: http://www.statesofawareness.net/pranayama
BTech thesis: Sahil Loomba and Shamiek Mangipudi
Blind content independent Image Quality Assessment (IQA) (Aug 2014):




Assessment of quality of a photograph of a natural scene or a portrait is done purely on perceptual grounds. The trained human eye does not need a reference to gauge the quality of a specific image or photograph presented to it. Some examples are given above. It is easy to see that the fourth image is of the highest quality as compared to others. The leftmost image [FOGGY ROAD] has low contrast, the second image [GRAZING HORSE] has noise the third one [BOY] suffers from some transmission distortion. But how would a human subject rank these pictures in terms of quality.
The research problem however is the process of automating this ranking process. In the absence of the original scene or photograph how would a machine (or signal processing unit) rate the quality of a particular image. This process has to be content independent and must mimic human perception. Very often the channel characteristics responsible for producing the distortion are not available. This makes the problem much more interesting as it has to be distortion model independent.
Ongoing BTech thesis projects (with publications):
a) Pranav Sodhani and Akshat Boradia - BLUR DETECTION and NOISE ESTIMATION
P. Sodhani, A. Bordia, K. Karthik, Blind Content Independent Noise Estimation for Multimedia Applications , Proceedings of International Multi-conference on Information Processing (IMCIP), Bangalore, Karnataka, 2015.
b) Harshit Gupta and Vishal Jha - NOISE PARAMETER ESTIMATION
Composite Biometric Hashing (November 2013):
Multi-modal biometric authentication is generally done at the score or decision level, where features from different biometrics are chosen independently and then quantized and hashed. Each biometric whether it is a fingerprint or a face has a distinct feature set which captures the variations across different classes of people (for example fingerprints use MINUTIAE and faces use singular points or outlines positioned around the EYES, NOSE, EARS and MOUTH). It is however difficult to find a common ground for associating the feature sets from two different modalities.

However, there exists very little literature, towards the identification of common feature space where two or more Biometrics can be combined. The motivation for finding a common feature space and then creating a composite biometric, at the expense of some compromise on the overall recognition rate could be the following:
- Compact storage with enhanced secrecy achieved by the mixing the features of two or more biometrics.
- Linking of one or more biometrics with the composite biometric without requiring all biometrics to be available at the same time.
One construction model for a composite biometric [ANI_DH_BTP2014] is by linearly combining features (taken from a common space) from two different biometrics such as faces and fingerprints with the help of random projection matrices.
[ANI_DHE_BTP2014] Anisha and Dheeraj, Composite biometric hashes , BTP thesis, May 2014.
Centre driven reconfigurable network for collaborative information processing (Jan 2013):
In collaborative information processing applications, a large computational task is delegated amongst several wireless nodes, by a centre. The main task is split into several sub-tasks and each subtask is assigned to a different group of nodes. Since the computation of each subtask entails a sharing of resources and may require further modularization, the nodes can form virtual groups for exchanging information and also for delegating roles amongst themselves. The information flow across virtual groups, group expansions, group migrations, group mergers, group dissolutions etc. can either be completely distributed or can be triggered by the centre. However when the nodes carry sensitive information (such as design information) and the overall computational task is confidential, the centre cannot afford to allow the nodes to form their own sub-groups to perform this distributed processing. This would make it difficult for the centre to monitor the flow and also perform intermediate checks on the information fragments exchanged amongst the nodes. In this framework we build on a centre driven reconfigurable network [KK_NSS_2013, VIG_ATI_BTP2014] where broadcast tokens and node shares of protected key blocks are designed to interact to release different keys in different nodes, creating virtual multicast groups amongst them. The focus of this research is on achieving control in key release [VIG_ATI_BTP2014] and also counteracting dynamics amongst nodes (accounting for nodes joining and leaving a particular multicast session), which raises issues pertaining to forward secrecy. Apart from completing the framework for secure collaborative processing, a rigorous security analysis addressing problems such as collusion and forward secrecy is expected.
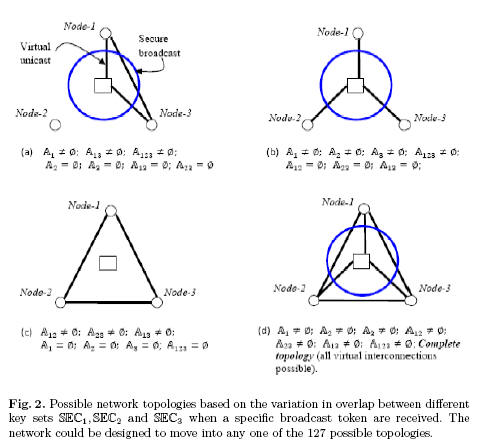 [Ref: KK_NSS_2013]
[Ref: KK_NSS_2013]
[KK_NSS_2013] K. Karthik, Virtually Reconfigurable Secure Wireless Networks using Broadcast Tokens , International Conference on Network Systems and Security (NSS 2013), Madrid, Spain, June 3-4, 2013.
[VIG_ATI_BTP2014] Vignesh and Atishay, Centre driven Controlled Evolution of Wireless Virtual Networks based on Broadcast Tokens , BTP Thesis, May 2014.
Reinforcing swarm behaviour for data/signal cleaning (November 2012):
Noisy data is ubiquitous as any natural signal acquisition process is bound to absorb (irrelevant details) i.e. noise along with pertinent signal information (relevant details). Signals emerging from natural or synthetic sources have a unique statistical signature, which is reflection of the intrinsic temporal, spatial or statistical redundancy inherent in the generation/synthesis process. Since the sources for noise are very different from the signal synthesis models, they acquire a characteristic which is very (or in some cases slightly) different from the actual signal itself. Most signal enhancement (or cleaning) techniques exploit these statistical differences to separate signal from noise. But what happens when noise and signal acquire the same statistical signature? Is separation possible? When the irrelevant components of a signal (due to the presence of noise) are seamlessly indistinguishable from the signal itself, there is a need to take an alternative route towards the signal cleaning process. What if it was known apriori that the majority of the received corrupted signal was pure (or clean)? Is it possible to trigger a swarm behaviour so that only the traits of the majority are enhanced and projected as the signal behaviour. This would require a careful expansion and contraction of the signal characteristics.
An application, is an example of node suveillance, where amongst several wireless sensor nodes, an unknown few are compromised and tend to seamlessly merge with the rest of the swarm. These few viral nodes, if undetected, will continue to inject cancerous signal variations which will blend with the other signals to quietly influence the overall computation and analysis. This form of node morphing is very difficult to detect and weed. But however, if the cleaning process selectively amplifies the traits of the majority uncompromised nodes, while suppressing that of the minority, the presence of these cancerous nodes can be nullified. This problem has been abstracted in the form of a binary source corruption formulation shown below, where each node is a binary source A or B or C:
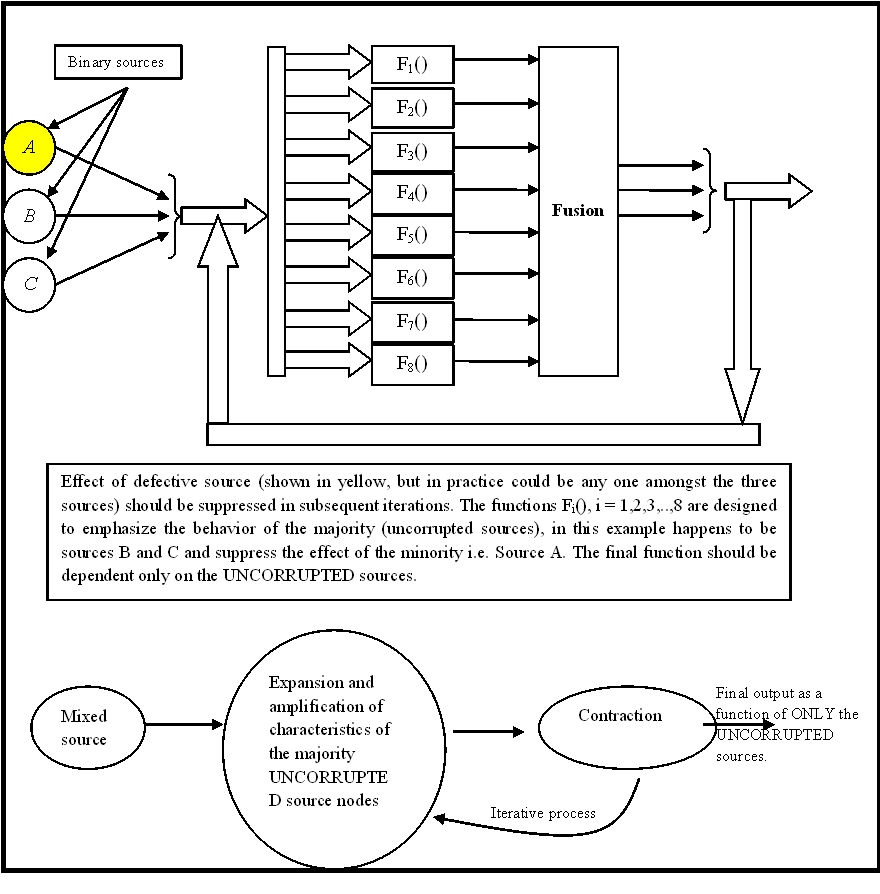
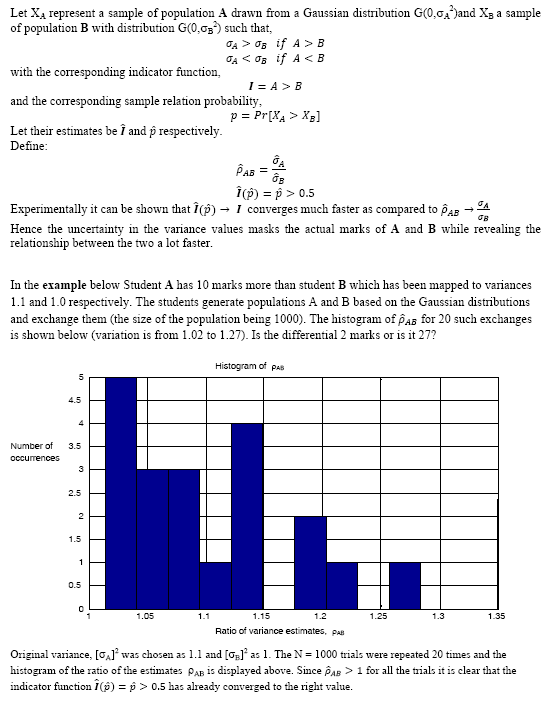
Partial knowledge protocols by statistical mapping (April 2012):
In some applications it is essential to find the relationship or association between two or more objects (signals/images/datasets) without revealing the actual values (or details) contained in these objects. The problem of revealing to another party the knowledge of a particular secret without revealing any information about the secret itself is that of the known Zero knowledge protocol which may be expressed as the millionaire's problem or that of a graph permutation problem. All Zero knowledge problems rely on computational infeasibility. However in the problem of statistical mapping the two objects A and B which need to be compared are used as seeds to grow a population based on certain statistical traits which are known to be consistent with the comparison measure. For instant if A and B represent the marks of two different students, the populations can be grown by mapping A to a Gaussian distribution having zero mean and variance proportional to the marks of A. A similar population can be grown for B.
Asymmetric watermarking (October 2011):
Detection of spread-spectrum watermarks is usually done through the process of correlation. If Y = X + W is the watermarked data, semi-blind detection is carried out by computing the inner-product with the watermark W itself (assuming that the receiver has a copy of it),
<Y, W> = <X, W> + <W, W> = 0 + Ew = Ew
Unfortunately this allows the receiver (detector) to engage in malpractices such as removing the watermark, particularly if the domain and type of embedding function are commonly known. A possible solution is to create asymmetric watermark embedding and detection mechanisms.
| Example (secure fingerprint detection): Create an orthogonal secret basis {W1, W2, W3} and construct watermarked copies for three users, as Y1 = X + W1 + W2, Y2 = X + W1 + W3 and Y3 = X + W2 + W3 .
Let the detection keys be, D1 = a11W1 + a13W3 , D2 = a22W2 + a23W3 and D3 = a31W1 + a33W2 (scaling factors can also be kept secret) Correlation Detection procedure is: <Yi, Di>, i = 1,2,3. Observe the mismatch in the detection keys with the original embedding scheme. If the traitor-receiver tries to remove the watermark by subtracting it, a trace will be left behind which will not only indicate that an act of manipulation has taken place, but may also be traced back to the receiver itself. There will be two asymmetric codebooks for the embedder and detectors, coupled with the design of the scaling parameters.
|
Asymmetric traitor tracing based on Eigen-decompositions (September 2011)
Conventionally in the problem of traitor tracing, a set of digital fingerprints are encoded and embedded in the original media (video, image or audio) in a specific domain such as the Spatial, Fourier, DCT or Wavelet. These fingerprints carry tracing information necessary to prosecute the user in case an act of piracy has been detected. To counter most pirates tend to engage in acts of collusion where several copies of the fingerprinted media are fuse either linearly or non-linearly to produce a pirated video/image. The process of collusion becomes more venomous when the embedding domain is known to the pirates. If a pirated copy is retrieved from circulation, it can be processed to detect traces of the fingerprints originally embedded in it. The knowledge of the fingerprint encoding and embedding process and the transform domain where the fingerprint traces are concealed is necessary for traitor tracing (i.e. tracking the users who have engaged in an act of piracy). But divulging so much of information to the verifier is a big risk. The verifier himself can erase the traces of any evidence with the side-information available. Thus the problem of conventional traitor tracing can be considered symmetric in nature where the knowledge of the embedding process at the time of verification can be misused for tampering with the evidence. Hence there is a need for distributing the trust between the source and the verifier. This can be implemented using the model below:
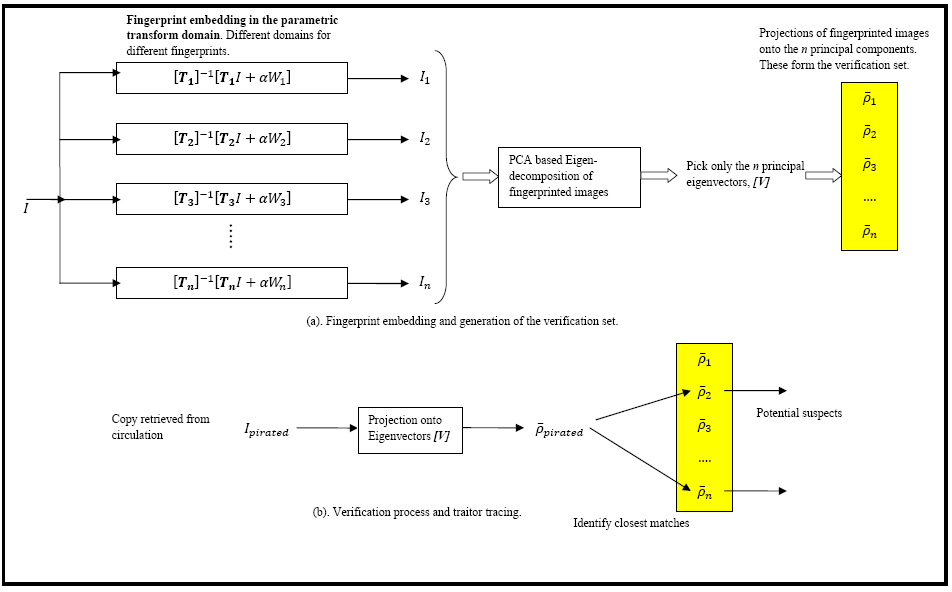
G. Praveen, A. Madhavaraj, K. Karthik, "A Code and Domain independent Traitor Tracing System based on the Eigen-decomposition of Fingerprinted Images", in International Conference on Image Information Processing (ICIIP 2011), Shimla, Himachal Pradesh, Nov 3-5 2011.
Anonymous verification and computing (August 2011)
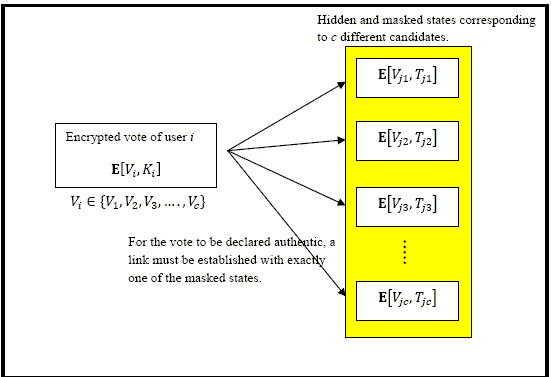
There are several large scale applications such as e-Voting, where it is necessary to prove the authenticity of a certain data fragment such as a vote cast by a user without being able to tap into the contents. The candidate picked by the user should remain unknown to the vote-verification unit. We may consider each candidate as a hidden state of the system and each user's encrypted vote as a deliberately corrupted version of one of the system states. The design must ensure that each encrypted vote should be linkable to exactly one of the states (assuming there are c different candidate-states). In the case of a vote manipulation or corruption, this link should either be weakened or severed, thus exposing the user responsible for the un-authentic vote. The votes which are functions of the hidden states cannot be directly compared with the states themselves since this would reveal the user's choice of candidate. Hence the votes must be compared with masked states. One possible model is shown below:
Fine-grained access control (Selective Access Codes - SACs) (June 2011): A K-out-of-n non-perfect secret sharing scheme can be designed so that all coalitions of shares having size less then K reveal very little (or no information) about the parent secret. On the other hand valid coalitions of size K can be designed to leak out partial information about the secret such that the information revealed by the coalition is unique to the subset. This property can be applied towards fine grained access with fingerprinting of sensitive health, government and business records or industrial designs. This can be achieved by controlled mixing of two bit-complementary binary strings X and Y = BIT_CMP[X]. The degree of granularity is called a partition (or opening), which consists of a subset of selective positions within the bit-string. Either by fusing a subset of shares or through an unlocking sequence, some of these partitions can be made visible, revealing the hidden sub-string within the main string. An example of such a selective access code is shown below (3-out-of-5). The SACs work in conjunction with certain rules.
Fine-grained access control application sketch:
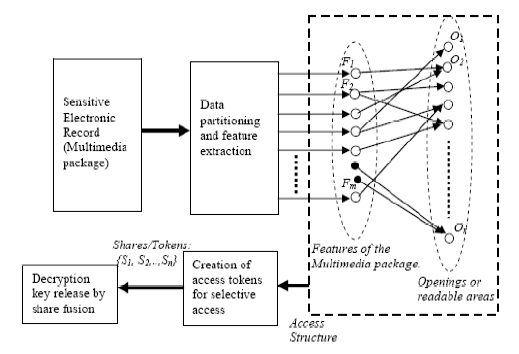
K. Karthik, "A Ramp Code for Fine-grained Access Control", in International Conference on Computer Science and Information Technology (CCSIT 2013), Bangalore, Karantaka, Feb 18-20, 2013.
Watermarking Transparent to Encryption (December 2010): Watermarking and encryption are normally treated as orthogonal processes, due to which detection of watermarks (for traitor tracing, authentication or copyright protection), is generally carried out in a standard transform domain (DCT, wavelets, DFT etc.) or in the spatio-temporal domain at the time of viewing. Watermarks serve a crucial role in binding information with the content, making information removal impossible without creating undue damage to the content itself. There is no disassociation between the content which is being tagged or protected and the watermark itself. In certain applications this form of binding is required in addition to content confidentiality. Confidentiality can be achieved through encryption, but the encryption must allow the watermark to be visible in the protected domain. An application is a search through a collection of medical images (MRI/CT scans) of various patients without gaining access to the contents. Shown below is an example of a transparent encryption scheme and the corresponding medical images. The challenges are mainly related to the vulnerability of the watermark to selective manipulation due to the extent of side-information that is available to detect its presence in both the encrypted domain and the decrypted domain.
![]()
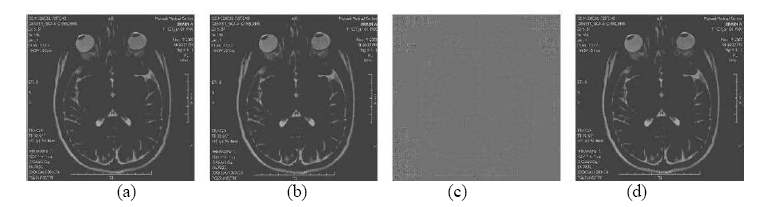
(a) Original image, (b) Watermarked, (c) Watermarked and encrypted, (d) Decrypted. Watermark containing the patient related details can be extracted from (b), (c) and (d).
A. Talwai, D. Sengupta, K. Karthik, A Transparent Encryption Scheme for Watermarked Biomedical and Medical Images , in International Conference on Signal Acquisition and Processing (ICSAP 2011), Singapore, February, 2011. [pdf]
Privacy preserving face-biometric comparison in the encrypted domain using soft-ciphers (November 2009)
The problem of extracting a portion of the image signature despite an intermediate encryption operation is challenging, since any cipher has a tendency to distort the statistics of the original image (or plaintext). By imposing certain constraints on the encryption process, it is possible to unlock certain statistical measurements involving the original image blocks either directly from the encrypted domain or by performing additional computations with the help of some side information. In the case of the former where a direct computation is involved, the cipher itself must be softened to allow a percolation of statistics such as the variance or global distribution/histogram of transform domain coefficients. As the cipher is strengthened by interleaving several rounds of permutation and substitution, the intrinsic statistical signature tends to dissipate in the encrypted domain and becomes virtually non-existent after a few rounds. There are two distinct classes of encryption schemes (Type-1) The conventional set of non-linear ciphers such as Triple-DES, AES etc. and (Type-2) Fundamental ciphers based on fundamental linear transformations such as permutation or some form of parametric substitution. Since ciphers like Triple-DES operate based on Shannon's fundamental principles of confusion and diffusion, every round increases the dimensionality or spread of the output space. Therefore, the initial clusters of correlated plaintexts (or image blocks), expand with every round of encryption and become more sparsely and uniformly distributed in the output space. In the context of privacy preserving image retrieval, we are interested in the second family of ciphers based on linear transformations (Type-2) as they have a tendency to preserve some structure of the original image, which can be used for comparing images in the encrypted domain.
Shown below is a typical example where the hash of the original Lena image and the encrypted version are the same. The cipher used here is a permutation cipher.

S. Kashyap, K. Karthik, Authenticating Encrypted Data , in National Conference on Communications (NCC 2011), Bangalore, India, January, 2011. [pdf]
Shown below is an example of an image retrieval process where the comparisons are performed in the encrypted domain. The cipher used here is a parametric substitution cipher.
The Essex-Male database has 337 faces from 114 different subjects. The number of variations per subject class is different for different classes. Following is the result of a submitted query to this database. The transformed query is supplied to the search engine.



K. Karthik, S. Kashyap, Transparent Hashing in the Encrypted Domain for Privacy Preserving Image Retrieval , Accepted in Springer Journal of Signal, Image and Video Processing, Special issue on Image and Video Processing for Security, 2013.
Generation of Cancelable Biometric Templates (2009):
Unlike a conventional cryptographic hash function in which even a single bit change in the message causes a complete change in the hash value, biometric hashes must be robust to geometric distortions of the registered fingerprint, ageing, dust particle interference etc. There are three main challenges: (1) Generating a set of features which are invariant to all forms of fingerprint distortions but highly sensitive to inter-class fingerprint variations (i.e. for fingerprints from different users); (2) Quantizing the features to generate the bio-hash codeword. Each feature can be individually quantized with a variable length code or all the features can be collated and jointly quantized using a vector quantizer. The decision boundaries which will be laid out shall decide the stability of the quantization process to incidental distortions; (3) Developing the hardware modules for fingerprint capture and hash computation.
The same bio-hash can be made cancelable by introducing some uncertainty in the feature acquisition process, for instance by (1) Choosing a random subset of features from the original feature set, (2) Identifying specific feature associations and using them as an abstraction of the original biometric itself. An example is the Minimum Distance Graph (MDG), which is an ordered set of inter-minutia minimum distances originating from the core. The Graph not only is robust to most intra user variations such as rotation, translation and cropping but also captures the diversity across users. Different user's thumbprints will yield completely different graphs. Minutia perturbation models can be used in conjunction with the MDG to create cancelable hashes.
P. Das, K. Karthik, B. C. Garai, A robust alignment-free fingerprint hashing algorithm based on minimum distance graphs , Elsevier Journal on Pattern Recognition,
Vol. 45, Issue 9, pp 3373-3388, 2012. URL: http://dx.doi.org/10.1016/j.patcog.2012.02.022 [pdf]
MDG Hash implementation from MINUTIA POINTS devoid of directional information:
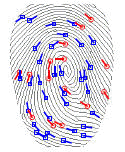

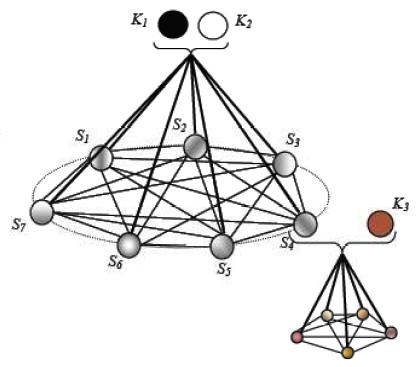
Non-perfect secret sharing schemes for group authentication (May 2009):
In a n-out-of-n non-perfect secret sharing scheme, the shares leak out some partial information about the parent secret. If this information is unique for different subsets of shares, this will allow each subset to be linked to the parent secret and will also give the subset a distinct identity. One application of such a framework is thus to construct group-authentication codes. An example of a (2,3)-authentication code which identifies subsets of shares {S1, S2}, {S2, S3}, {S1, S3} and {S1, S2, S3} is shown in the geometric representation below.
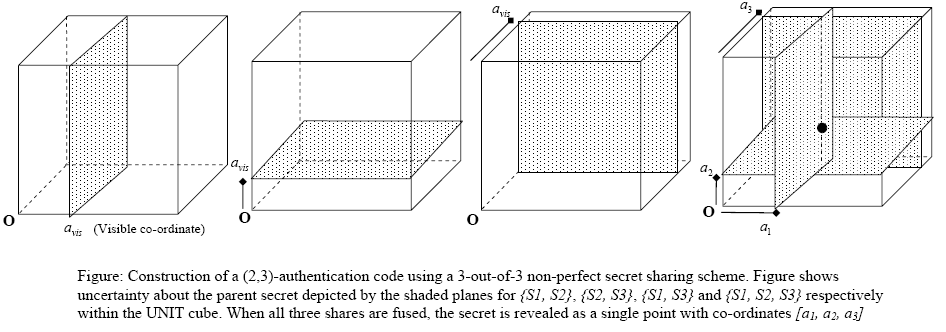
The above construction is discussed in more depth in the publication:
K. Karthik, D. Hatzinakos, "Secure Group Authentication Using a Non-perfect Secret Sharing Scheme based on Controlled Mixing", Proceedings of INDICON 2009, Gandhinagar, Gujarat, Dec 18-20, 2009.[pdf]
Uncovering trends in datasets and identifying patterns for "Googling" images from databases (May 2009):
Given a specific "query phrase", "sentence" or "set of words", the problem of identifying the most likely page-matches is well established and popularly termed as "Googling". With a well established language model, one can learn the first-order, second-order and nth-order dependencies between any subset of words and characters. Searching for a given phrase essentially means discovering the same association between a select group of words across numerous pages in the world wide web (WWW). While similarity between "two phrases" can be more clearly defined in the case of text, it become extremely challenging in the case of images. This is mainly because the notion of perceptual similarity is a humanoid function, very difficult to automate and measure. The query image itself may be in a crumpled state (e.g. partially blurred, low intensity, small noisy image), while the target image(s) may have a superior quality and could be of a much larger size. Making the image search and comparison process, size-invariant, immune to geometric distortions and noise is challenging. The real question is whether it is possible to construct a small binary PIN (robust hash) of any arbitrary image and use these PINs for navigating through image databases.
One possible approach is by creating multiple abstractions of a particular image by first downsampling into several child images and then filtering the derived child-sets differently to form different abstracted pseudo-images. By comparing these abstractions a binary PIN can be constructed. Robustness to geometric distortions can be absorbed into the downsampling process.
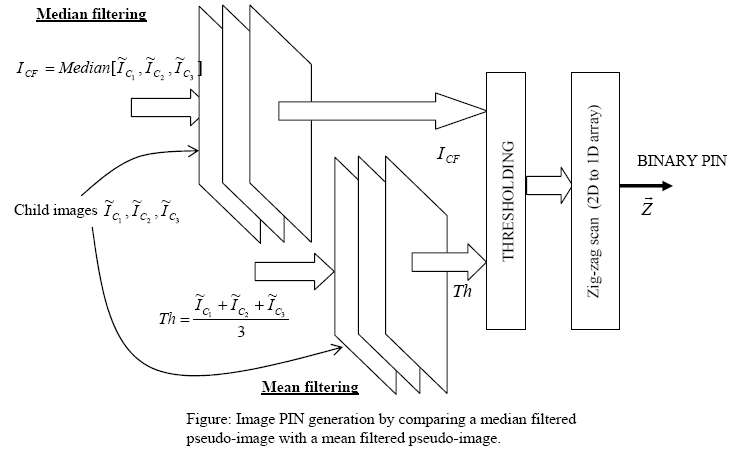
K. Karthik, "Constructing Intrinsic Image Signatures by Random Downsampling and Differential Mean-Median Information, Accepted in International Journal of Tomography and Statistics (IJTS 2012), 2012.
K. Karthik, "Robust Image Hashing by Downsampling: Between Mean and Median", proceedings of World Congress on Information and Communication Technologies (WICT 2011), Mumbai, Maharashtra,
Dec 11-14 2011.
Properties and applications of MIX-SPLIT (2007)
The MIX-SPLIT algorithm is a non-perfect secret sharing scheme, which merges two statistically similar binary sequences into a closed subset of n shares through a carefully designed codebook. It has several interesting properties: (1) Association, (2) Inheritance, (3) Anonymity with traceability and (4) Closure. Search for potential applications which require both access control along with traitor tracing is on. Examples could include (1) Controlling and tracking e-prescriptions, and more sophisticated applications such as (2) Anonymous E-voting.
Excerpts of the MIX-SPLIT algorithm including some potential applications are highlighted in the following papers:
K. Karthik, D. Hatzinakos, A Unified approach to construct Non-perfect Secret Sharing and Traitor Tracing schemes , in Proceedings of International Conference on Security and Management (SAM 07), Las Vegas, Nevada, June 25-28, 2007. [pdf]
K. Karthik, D. Hatzinakos, MIX-SPLIT: Controlled Mixing of Secrets and Traceable Pseudonym Generation using Codebooks , in Proceedings of Workshop on Information Forensics and Security, (WIFS 10), Seattle, Washington, Dec, 2010. [pdf]
Constructing anti-collusion codes tailored to a specific watermark modulation scheme (2007): Very often the anti-collusion code design problem is treated orthogonal to the watermark embedding process. The problem with this view is that it becomes extremely difficult to gauge the erasure pattern of the concealed codeword which is disturbed by a collusion attack. A better understanding of codeword erasures in the bit domain due to spatial domain collusions, will permit the source (or distributor) to design more compact codebooks and accurately track the set of traitors by carefully analyzing the erasure patterns. The key to solving this problem is to identify a suitable transform domain where a collection of semi-fragile watermarks can be embedded, whose survival in a particular domain is based on numerical dominance (i.e. purely in terms of numbers) amongst an arbitrary sub-group of traitors. The semi-fragile watermarks from this collection must be distributed differently across different groups of users so that there is a unique (traceable) association between any subset of users.
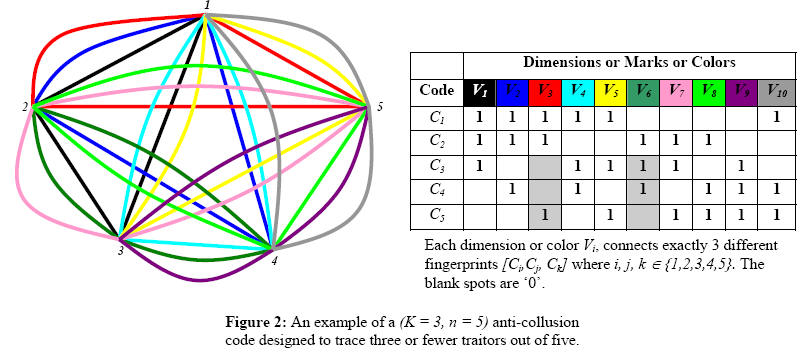
This has been split into two interconnected problems: (1) Design of transform domain specific anti-collusion codes, (2) Identification of a secret parametric transform domain where the semi-fragile watermarks can be concealed. A more detailed problem description is given HERE.
Related publication on how to marry the anti-collusion code design with the embedding methodology is,
K. Karthik, D. Hatzinakos, A novel anti-collusion coding scheme tailored to track linear collusions , in International Workshop on Data Hiding for Information and Multimedia Security (DHIMS 07), Manchester, UK, Aug 29-31, 2007.[pdf]